![[AI] 모델 성능 개선](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2Fbn9HX0%2FbtsG35zXhTC%2FEY1vioxvdNwYo0W8xKRQ7K%2Fimg.png)
안녕하세요. 개발자 Jindory입니다.
오늘은 머신러닝의 모델 성능 개선에 대해서 글을 작성해보려고 합니다.
글에 앞서 본 글은 멀티캠퍼스의 "핵심만 쏙! 실무에 바로 적용하는 머신러닝"의 강의를 참고하여 작성한 내용임을 밝힙니다.
[ 글 작성 이유 ]
AI 관련 강의를 수강하며, 머신러닝과 관련된 개념 및 설명을 정리하고자 작성하게 되었습니다.
1. 머신러닝 모델 성능개선
데이터 학습을 통해 만든 모델이 적정 수준의 성능에 도달하지 못할 경우, 목표한 성능으로 향상시키기 위해 진행하는 절차를 모델 성능 개선이라고 합니다. 그렇다면 모델의 성능이 일정 수준에 도달하지 못한 상태를 어떻게 정리할 수 있을까요? 강의에서는 부적합(UnderFitting)과 과적합(OverFitting)으로 정의를 했습니다.
- 부적합(UnderFitting)

참조 :https://wikidocs.net/196840 - 이는 모델이 단순하게 그려졌을때, 혹은 제대로 학습되지 않아 나타나는 현상입니다.
- 실제 데이터를 적용했을때 원하는 결과를 제대로 예측하지 못하는 결과가 나타납니다.
- 위 그림처럼 모델의 데이터의 경향성을 제대로 파악하지 못 하여, 원하는 결과를 도출하지 못한 상태를 나타냅니다.
- 과적합(OverFitting)
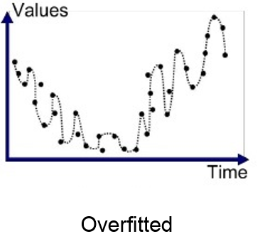
참조 : https://wikidocs.net/196840 - 모델이 데이터 사이의 의존성에 너무 기인하여, 복잡하게 학습된 경우 발생하는 현상입니다.
- 학습데이터에의 성능은 좋지만 실제 데이터에 대해 성능이 떨어지는 현상입니다.
- 주로 학습한 데이터를 너무 과도하게 학습하는 경우 발생하는 현상입니다.
- 위 그림처럼 모델이 데이터에 과하게 의존하여, 일반적인 경향성 보다는 데이터에 맞춰서 모델이 학습되어, 일반 데이터 적용시 성능이 잘 나오지 않는 상태를 나타냅니다.
이러한 모델 성능을 개선의 방법에는 데이터 품질 개선, 모델 변경, 모델 파라미터 개선 등 다양한 방법이 있습니다.
1.1 모델 성능 개선 방법(데이터)
머신러닝 모델의 성능을 개선하는 방법 중 먼저 데이터를 개선하는 방법에 대해서 정리해 보겠습니다. 데이터를 개선하는 방법에는 데이터 정제, 데이터 통합, 데이터 변환, 데이터 축소 등의 방법이 있습니다.

1.1.1 데이터 정제(Data Cleaning)
학습 데이터를 통해 모델이 만들어지므로, 모델 학습에 있어서 불필요하다고 생각되는 데이터들을 제거하는 방법입니다.
- 결측치 처리(Missing Value Imputation): 데이터에서 결측치를 제거하거나 평균, 중앙값, 최빈값 등으로 채우는 기법을 말합니다. 또한, 예측 모델을 사용하여 결측치를 예측하여 채우는 방법도 있습니다.
- 이상치 탐지 및 처리(Outlier Detection and Handling): 데이터에서 통계적 기법(예: IQR, Z-score)을 사용하여 이상치를 탐지하고, 제거하거나 수정함으로써 데이터의 품질을 개선합니다.
- 잡음 제거(Noise Filtering): 데이터 스무딩 기법을 사용하여 잡음이 포함된 데이터를 정제합니다. 예를 들어, 이동 평균(Moving Average)이나 중간값 필터(Median Filter) 등이 있습니다.
1.1.2 데이터 통합(Data Integration)
데이터들 중 중복된 데이터 혹은 비슷한 속성의 데이터를 통합하여 데이터를 정리하는 방법입니다.
- 중복 제거(Duplicate Elimination): 데이터셋 내의 중복된 레코드를 식별하고 제거하여 데이터의 일관성을 유지합니다.
- 데이터 통합(Data Merging): 여러 출처에서 온 데이터셋을 통합하여 하나의 일관된 데이터셋을 생성합니다. 이 과정에서 스키마 통합, 엔티티 해석 등의 작업이 수행됩니다.
1.1.3 데이터 변환(Data Transformation)
데이터 Feature의 값이 절대적인 수치가 차이가 날 수 있으므로, 각각의 Feature가 동일한 가중치로 반영될 수 있도록 변형하는 방법입니다.

- 정규화(Normalization): 데이터의 스케일을 일정한 범위 내로 조정합니다(예: 0과 1 사이). Min-Max 스케일링, Z-score 정규화 등이 있습니다.
- 표준화(Standardization): 데이터가 평균 0, 분산 1을 갖도록 변환합니다. 이는 모델이 데이터를 더 잘 이해하도록 돕습니다.
- 범주형 데이터의 수치화(Encoding Categorical Data): 범주형 데이터를 모델이 이해할 수 있는 수치형 데이터로 변환합니다. 원-핫 인코딩(One-Hot Encoding), 레이블 인코딩(Label Encoding) 등이 있습니다.
1.1.4 데이터 축소(Data Reduction)
데이터의 특성을 유지하면서 계산의 복잡성을 줄이고자 사용하는 방법입니다.

- 차원 축소(Dimensionality Reduction): PCA(주성분 분석), LDA(선형 판별 분석) 같은 기법을 사용하여 데이터의 차원을 축소합니다. 이는 계산 비용을 줄이고, 과적합을 방지하는 데 도움이 됩니다.
- 데이터 샘플링(Data Sampling): 데이터의 양을 줄이면서도 데이터의 특성을 유지하기 위해 표본을 추출하는 방법입니다. 이는 특히 대규모 데이터셋을 다룰 때 유용합니다.
1.1.5 데이터 교차 검증(Data Cross Validation)
데이터 교차 검증은 모델의 성능을 평가하고 일반화 능력을 향상시키기 위해 사용하는 기법입니다. 학습 데이터를 여러개의 데이터 셋으로 나누고, 아래의 그림과 같이 번갈아 가면서 학습 및 검증을 수행하여, 현재 모델이 데이터에 대해서 성능을 잘 발휘하고 있는지 확인할 수 있는 방법입니다.
1.2 모델 성능 개선 방법(모델)
다음으로 머신러닝 모델의 성능을 개선하는 방법 모델을 개선하는 방법에 대해서 정리해 보겠습니다. 모델을 개선하는 방법에는 하이퍼파라미터 튜닝, GridSearch, GridSearchCV가 있습니다.
1.2.1 하이퍼 파라미터 튜닝
머신러닝 모델이 학습을 통해 스스로 찾아내는 값을 사람이 직접 설정하는 방법입니다.
예를들어 노드의 수, Feature의 가중치, 은닉층의 개수, 학습률 등을 사람이 직접 조절하여 원하는 모델이 원하는 성능이 나올때까지 사람이 직접 조절하는 방법을 의미합니다.

1.2.1.1 GridSearch
하이퍼파라미터를 자동으로 조절하는 방법으로 모델을 구성하는 관심 있는 변수들을 대상으로 가능한 모든 조합을 시도해서 모델을 만드는 방법입니다. 여러개의 조합을 시도해 봤을때 가장 성능이 좋게 나오는 조합을 하이퍼파라미터를 선택합니다.

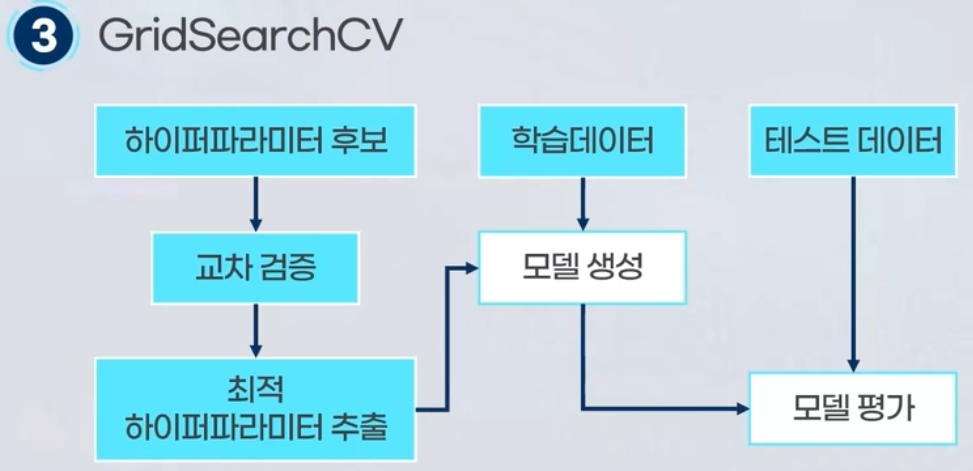
1.2.1.2 GridSearchCV
GridsSearch와 Cross Validation의 개념을 함께 적용하여, 일반화 성능을 개선하는 방법입니다. 먼저 하이퍼 파라미터 후보를 선별하고, 학습데이터를 여러개의 데이터 셋으로 구분한 후 교차검증을 진행합니다. 교차검증을 진행하며, 최적의 하이퍼 파라미터를 추출하여 해당 하이퍼파라미터 설정으로 다시 학습데이터를 학습하여 모델을 생성합니다.
이렇게 머신러닝의 모델 성능 개선에 대해서 알아봤습니다.
혹시라도 정정할 내용이나 추가적으로 필요하신 정보가 있다면 댓글 남겨주시면 감사하겠습니다.
오늘도 Jindory 블로그에 방문해주셔서 감사합니다.
[참조]
- [멀티 캠퍼스] 핵심만 쏙! 실무에 바로 적용하는 머신러닝
'개발 > AI' 카테고리의 다른 글
| [AI] 연관분석 (0) | 2024.05.13 |
|---|---|
| [AI] 군집분석 (0) | 2024.05.08 |
| [AI] 회귀모델 (0) | 2024.04.10 |
| [AI] 분류모델 (0) | 2024.04.06 |
| [AI] 머신러닝이란? (0) | 2024.04.06 |