![[AI] 분류모델](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FCAAjQ%2FbtsGpqdMRxO%2FcInPh8h4ljEiOqXChXR5Ek%2Fimg.png)
안녕하세요. 개발자 Jindory입니다.
오늘은 머신러닝의 분류모델 대해서 글을 작성해보려고 합니다.
글에 앞서 본 글은 멀티캠퍼스의 "핵심만 쏙! 실무에 바로 적용하는 머신러닝"의 강의를 참고하여 작성한 내용임을 밝힙니다.
[ 글 작성 이유 ]
AI 관련 강의를 수강하며, 머신러닝과 관련된 개념 및 설명을 정리하고자 작성하게 되었습니다.
1. 분류모델이란(Classification Model)?
분류모델을 알아 보기에 앞서, 분류에 대해서 간단히 알아볼까요?
분류란 "물건이나 사물, 개념 등 개체를 비슷한 것끼리 묶어서 구분하는것"을 분류라고 합니다.
예를 들어 아래의 과일을 분류한다고 했을때, 몇가지 기준에 따라 분류가 가능합니다.
분류할 과일 : 사과,배,딸기,바나나,포도,귤,레몬,복숭아,블루베리,키워
- 이름의 글자수로 분류하기
- 한글자인 과일 : 배,귤
- 두글자인 과일 : 사과,딸기,포도,레몬,키위
- 세글자인 과일 : 복숭아
- 네글자인 과일 : 블루베리
- 색으로 구분하기
- 붉은 계열 과일 : 사과,딸기
- 노란 계열 과일 : 배,바나나,귤,레몬,복숭아
- 푸른 계열 과일 : 포도,블루베리,키위
이처럼 특정 대상을 기준을 가지고 비슷한것끼리 묶는 작업을 "분류"라고 합니다.
그래서 분류 모델은 데이터를 특정 카테고리로 분류하는 작업을 수행하는 알고리즘을 말합니다. 이 모델은 주로 지도학습에서 사용되며, 입력한 데이터와 해당 데이터의 정답 데이터를 함께 학습하여 새로운 입력이 들어왔을때 해당 카테고리를 예측합니다.
이러한 분류모델에는 어떤 모델들이 있는지 하나씩 알아보도록 하겠습니다.
1.1 의사결정나무(Decision Tree)
의사결정나무는 주어진 입력값들에 대해서 의사결정규칙에 따라서 유형을 분류 예측하는 모형입니다. 주로 아래와 같이 트리모양으로 표현되며, 각각의 결정 규칙을 거치면서 데이터가 특정 분류로 분류되도록 설계된 모델입니다.

1.1.1 특징
의사결정 나무는 아래와 같은 특징을 가지고 있습니다.
- 의사 결정 규칙을 나무 구조로 나타내어 전체 자료를 몇 개의 소집단으로 나눈어 예측이 가능하다.
- 다른 모델들에 비해 직관적이고 간결한 알고리즘이다.
- 예측 정확도는 다른 지도 학습 기법들에 비해 대체로 떨어지나 해석이 수월하다는 장점을 가지고 있다.
- 분류(Classification)와 회귀(Regression)에 모두 사용될 수 있다.
1.1.2 의사 결정나무 분류 기준
그렇다면 의사결정 나무 모델의 분류 기준은 어떻게 만들어지는걸까요? 의사결정나무의 분기 기준에 대해서 설명해 보도록 하겠습니다.
- 분리기준(Splittting Creteria)
- 의사결정나무는 각 노드에서 지니지수(Gini Index)나 엔트로피(Entropy) 지수로 구한 불순도를 기준으로 트리를 분할합니다.
- 분리 기준은 부모 노드보다 자식 노드의 순수도(불순도를 감소)를 최대화하도록 선택됩니다.
- 이를 통해 입력 공간을 분할하여 더 명확한 패턴을 찾습니다.
- 순수도(Purity)
- 순수도는 목표 변수의 특정 범주에 개체들이 얼마나 포함되어 있는지를 나타냅니다.
- 데이터가 특정 범주에 얼마나 깔끔하게 속해 있는 정도를 나타냅니다.
- 불순도를 최소화하고 순수도를 최대화하는 분리 기준을 찾습니다.
- 분기수(Depth)
- 의사결정나무는 깊이를 가지며, 가지를 이루고 있는 노드의 개수를 의미합니다.
- 깊이가 깊어질수록 더 복잡한 규칙을 생성하게 됩니다.
1.1.3 의사 결정나무 프로세스
그럼 의사결정 나무 모델을 학습하는 과정에 대해서 알아보도록 하겠습니다.
의사결정나무는 의사결정 나무 기본 틀 생성, 프루닝, 교차검증, 평가 등 4가지 단계로 이루어집니다.

- 의사결정 나무 기본틀 생성
- 데이터의 불순도(데이터의 범주가 여러개인 상태)가 낮아지도록 가지를 설정하여, 목표하고자 하는 범주로 나눠지도록 분기 조건을 설정합니다.
- 이때 사용되는것이 엔트로피계수와 지니계수 그리고 분류오류율 등이 있습니다.
- 엔트로피계수
- 데이터의 불순도를 측정하는 지표로써 데이터 집합의 무질서한 정도를 나타냅니다.
- 엔트로피가 낮을수록 데이터가 순수하고 분류가 잘 되었다고 해석할 수 있습니다.
- 엔트로피 계수를 구하는 공식
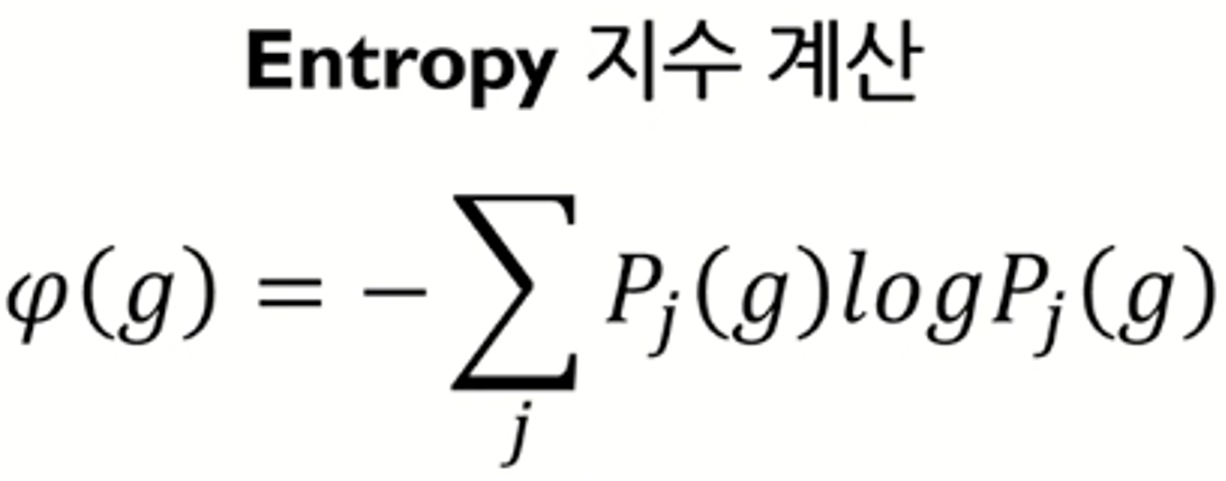
- 지니계수
- 데이터의 통계적 분산 정도를 정량화 하여 측정한 값으로 불순도를 측정하는 지표입니다.
- 지니 계수가 낮을수록 데이터가 순수하고 분류가 잘 되었다고 해석할 수 있습니다.
- 지니계수 구하는 공식

- 분류 오류율
- 분류 오류율은 잘못 분류된 데이터의 비율을 나타냅니다.
- 분류 오류율이 낮을수록 모델의 예측력이 높다고 할 수 있습니다.
- 프루닝(가지치기)
- 분별력이 약한 가지를 제거하는 방식입니다.
- 모델의 깊이나 가지의 개수를 지정하여 특정 깊이 이상 혹은 가지의 갯수 이상으로 만들어지지 않도록 가지를 제거합니다.
- 학습이 완료된 이후에 불필요한 가지를 제거하여 과적합을 방지하는 방법도 있습니다.
- 교차검증

- 학습용 데이터와 테스트용 데이터의 역할을 바꿔가며 일반화 성능 측정합니다.
- 이를 위해서 데이터를 여러 부분으로 나누고, 각 부분을 훈련과 검증에 번갈하 사용하여 모델을 평가합니다.
- 평가
- 정제된 모형을 사용하여 평가 및 예측
1.2 앙상블 모델(Ensemble Model)
앙상블 모델을 이해하는데 앞서 "앙상블"의 의미부터 찾아볼까요?
앙상블(Ensemble)이란 프랑스어로 전체적인 어울림이나 통일. '조화'로 순화한다는 의미의 프랑스어이며 음악에서 2인 이상이 하는 노래나 연주하는것을 의미합니다. 이러한 앙상블이라는 개념을 머신러닝에 적용해 본다면 여러가지 머신러닝 알고리즘을 조합해서 좋은 성능을 내는 알고리즘을 만드는 과정을 일컫어 앙상블 모델이라고 하는것 같습니다.
1.2.1 특징
앙상블 모델은 아래와 같은 특징을 가지고 있습니다.
- 여러개의 예측 모형을 만든 후 이를 조합하여 하나의 최종 예측 모형을 만듭니다.
- 이를 통해 각 모델의 장점을 활용하고 단점을 보완합니다.
- 이는 개별 모델의 예측 오류를 상쇄하고 일반화 능력을 향상시킵니다.
1.2.2 Voting Process
앙상블 모델이 하나의 결과값을 내기 위해서 하는 과정을 Voting이라고 하며, 이 Voting에 대해 하드보팅(Hard Voting)과, 소프트보팅(Soft Voting)이 있어서 각 각을 정리해 보도록 하겠습니다.
- 하드보팅(Hard Voting)

- 여러 개의 분류기가 예측한 결과 중 가장 많은 표를 얻은 클래스를 최종 예측 결과로 선택하는 방법입니다.
- 다수결의 원칙을 기반으로 하여 가장 많은 예측결과를 채택합니다.
- 이는 이진 분류와 다중 클래스 분류 모두에 적합합니다.
- 소프트보팅(Soft Voting)

- 각 분류기가 예측한 클래스의 확률을 평균하여 가장 높은 확률을 가진 클래스를 최종 예측 결과로 선택합니다.
- 이 방법은 확률을 기반으로 합니다.
- 주로 확률을 반환하는 모델에서 사용됩니다.
1.2.3 배깅(Bagging)
Bagging은 Bootstrap Aggregationg의 약어로 다수의 분류기를 독립적으로 학습시킨 후 그 예측을 결합하여 더 적확한 예측을 만드는 방법입니다. 데이터를 랜덤하게 데이터를 샘플링하여 N개의 데이터로 추출한 후 N개의 분류기기를 만들어 개별학습 한 후 최종적으로 의사결정하는 방식입니다.
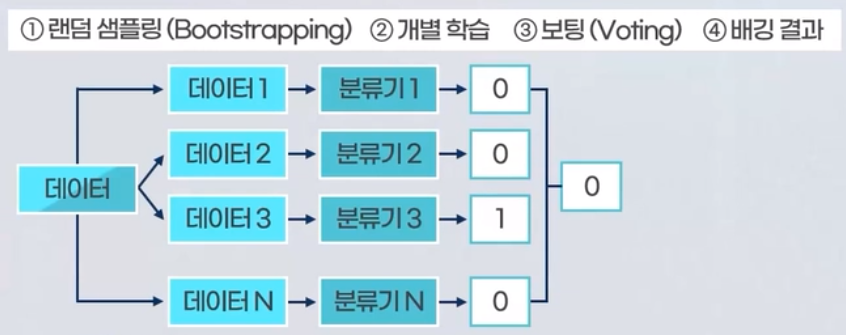
- Bagging방식의 하나로 랜덤 포레스트(Random Forest) 모델이 있습니다.
- 여러개의 의사결정 나무의 다수결을 통해서 모델의 성능을 개선한 앙상블 모델입니다.
- 높은 정확도와 과접합 문제를 해결한 방법이라고 할 수 있습니다.

1.2.4 부스팅(Boosting)
각각의 모델에서 오분류한 학습데이터를 다음 모델에 빌드될 때 학습 튜플로 선택되어질 가능성을 높여줘서 다음 모델에서 오류에 대한 보완하는 방법 모델입니다.
아래의 그림에서와 같이 1번 분류기에서 오분류된 데이터의 가중치를 반영하여 데이터2번에 반영되어 2번 분류기에서 잘 분류될 수 있도록 가중치를 높이는 방식을 사용합니다.
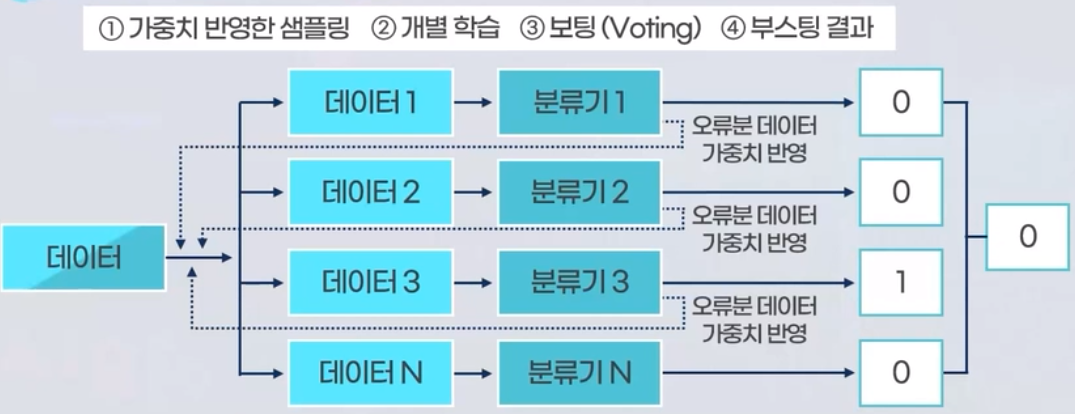
- Boosting방식의 하나로 그래디언트 부스팅(Gradient Boosting) 모델이 있습니다.
- 이전 학습의 결과에서 나온 오차를 다음 학습에 전달해 이전의 오차를 점진적으로 개선하는 기법입니다.
- 실제값과 예측값의 차이인 잔차를 학습해 나가며 잔차를 줄여나가는 방식입니다.

출처 : GitHub - benedekrozemberczki/awesome-gradient-boosting-papers: A curated list of gradient boosting research papers with implementations.
1.3 분류 모델의 평가
다음으로 분류모델이 잘 만들어졌는지 평가하는 방법에 대해서 알아보도록 하겠습니다. 분류모델의 성능을 평가하는 방법으로 혼동행렬(Confusion Matrix)를 사용하는데, 혼동행렬은 아래의 그림과 같습니다.
1.3.1 혼동행렬(Confusion Matrix)
혼동행렬이란 분류 모델이 분류를 얼마나 헷갈리고 있는지를 확인할 수 있는 지표라고 할 수 있습니다. 데이터를 예측한 값과 실제값을 두고 긍정과 부정으로 나누었을때 아래의 4가지 경우가 나올 수 있습니다.

- True Positive : 실제값이 긍정인데, 예측값도 긍정인 경우
- True Negative : 실제값이 부정인데, 예측값도 부정인 경우
- False Positive : 실제값이 부정인데, 예측값이 긍정인 경우
- False Negative : 실제값이 긍정인데, 예측값이 부정인 경우
위 기준을 통해 모델이 얼마나 예측을 혼동하고 있는지, 얼마나 잘 예측하고 있는지 확인하는 지표로 활용됩니다. 또한 이 Confustion Matrix로 나온 결과값을 바탕으로 아래와 같은 수식을 만들 수 있습니다.

- 정확도(Accuracy) : 전체 예측 중 올바른 예측의 비율을 나타냅니다. 가장 직관적을 모델 성능을 이해할 수 있는 지표입니다. 그러나 데이터 클래스 불균형이 있을 경우 정확도만으로는 모델의 선능을 제대로 평가하기 어렵습니다.(암환자 예측 데이터중 98%가 정상데이터 2%가 암환자 데이터인 경우 아무렇게나 예측해도 98%의 정확도가 나올 수 있음)
- 정밀도(Precision)
- 양성으로 예측된 결과 중 실제로 양성인 비율을 나타냅니다. 모델이 얼마나 정확하게 양성 클래스를 예측하는지를 나타내는 지표입니다.
- 거짓 양성이 큰 비용을 초래하는 경우에 사용됩니다.
- 정확한 양성 예측이 중요한 경우에 사용됩니다.
- 예시 : 만일 스팸 메일을 분류하는 모델을 만든다고 했을때, 정밀도가 높은 모델인지가 중요할 것입니다. 스팸이 아닌 줄 알았는데 스팸인 경우 휴지통에 버리면 끝나지만, 스팸인줄 알았는데 실제로 아니었을 때 그 메일이 중요한 메일인 경우 거액의 거래를 놓칠 수 있는 문제가 발생할 수 있기 때문입니다.
- 재현율(Recall) :
- 실제 양성 중 모델이 양성으로 예측한 비율을 나타냅니다. 모델이 실제 양성 클래스를 얼마나 잘 찾아내는지를 나타내는 지표입니다.
- 거짓 음성을 최소화 해야하는 경우에 사용합니다.
- 실제 양성을 빠르게 찾아내야 하는 경우에 사용합니다.
- 예시 : 만일 암진단 예측하는 모델을 만든다고 했을때, 재현율이 높은 모델인지가 중요할 것입니다. 암인줄 알았는데 실제로 아닌 경우에 대해서는 일정의 해프닝으로 끝날 수 있지만, 암이 아닌줄 알았는데 실제로 암인 경우에는 치료시기를 놓쳐 위험한 상황으로 갈 수 있기 때문입니다.
이렇게 머신러닝의 분류모델에 대해서 알아봤습니다.
혹시라도 정정할 내용이나 추가적으로 필요하신 정보가 있다면 댓글 남겨주시면 감사하겠습니다.
오늘도 Jindory 블로그에 방문해주셔서 감사합니다.
[참조]
- [멀티 캠퍼스] 핵심만 쏙! 실무에 바로 적용하는 머신러닝
'개발 > AI' 카테고리의 다른 글
| [AI] 연관분석 (0) | 2024.05.13 |
|---|---|
| [AI] 군집분석 (0) | 2024.05.08 |
| [AI] 모델 성능 개선 (0) | 2024.05.02 |
| [AI] 회귀모델 (0) | 2024.04.10 |
| [AI] 머신러닝이란? (0) | 2024.04.06 |