![[AI] 회귀모델](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FnVWKr%2FbtsGvvywFwX%2FS1EopHBhXDX7zhCE8HcFKK%2Fimg.png)
안녕하세요. 개발자 Jindory입니다.
오늘은 머신러닝의 회귀모델 대해서 글을 작성해보려고 합니다.
글에 앞서 본 글은 멀티캠퍼스의 "핵심만 쏙! 실무에 바로 적용하는 머신러닝"의 강의를 참고하여 작성한 내용임을 밝힙니다.
[ 글 작성 이유 ]
AI 관련 강의를 수강하며, 머신러닝과 관련된 개념 및 설명을 정리하고자 작성하게 되었습니다.
1. 회귀모델이란(Regression Model)?
회귀모델을 알아 보기에 앞서, 회귀에 대해서 간단히 알아볼까요?
1.1 회귀모델의 정의
회귀(Regression)이란 "하나 이상의 변수가 다른 변수에 미치는 영향을 알아보는 통계기법"입니다. 쉽게 말하면 발이 큰 사람들이 키도 클까요?라는 질문에 대해서 발 크기와 키의 상관관계를 알아내는 방법이라고 할 수 있습니다. 사전적 설명으로는 "독립변수(independent variable) 또는 예측인자(predictor)라 부르는 변수 X와 종속변수(dependent variable) 또는 예측량(predictand)이라 부르는 변수 Y의 관계를 함수식으로 설명하는 통계적 방법이다." 라고 나와 있습니다.
회귀의 정의에서 나오는 독립변수와 종속 변수에 대해 헷갈리는 분들도 계실테니 아래와 같이 간략히 정리하고 넘어가겠습니다.
- 독립변수 (Independent Variable): 이 변수는 연구자가 의도적으로 변화시키는 변수입니다. 다시 말해, 원인이 되는 변수입니다. 예를 들어, 날씨에 따라 아이스크림 판매량이 변한다고 가정해보겠습니다. 여기서 날씨는 독립변수입니다. 연구자가 날씨를 조작하여 아이스크림 판매량에 어떤 영향을 미치는지 알아보는 것이죠.
- 종속변수 (Dependent Variable): 이 변수는 연구자가 독립변수의 변화에 따라 알고싶어하는 결과 변수입니다. 다시 말해, 결과가 되는 변수입니다. 위의 예시에서는 아이스크림 판매량이 종속변수입니다. 날씨에 따라 아이스크림 판매량이 어떻게 변하는지 관찰하고 분석합니다.
회귀모델의 방정식은 아래와 같이 표현할 수 있습니다.
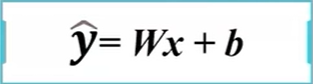
회귀분석은 회귀식을 찾는 통계적 기법인데 쉽게 말해서 아래의 그림의 파란 점선을 찾아가는 과정이라고 이해하면 됩니다.
초록색 점이 실제 데이터이고, 파란색 점선이 회귀식이며, 초록색 점과 점선의 차이가 적을수록 좋은 회귀식이 만들어졌다고 생각하면 될 것 같습니다.

독립변수 x에 대해서 종속변수 y의 값을 구하는 W(가중치)를 구하는것이 회귀 모델의 목적이라고 할 수 있습니다. 주어진 y의 값과 x의 값을 대입해보면서 회귀모델은 w값을 스스로 찾아내는데 이 과정을 "파라미터 추정"이라고 표현할 수 있습니다.
파라미터 추정을 할 때 비용 함수의 최솟값을 찾아내면서 W값과 b값을 최종적으로 찾아낼 수 있게 됩니다.
1.2 회귀모델의 특징
회귀에는 2가지 타입이 있는데, 하나는 선형회귀(Simple Linear Regression)이고, 다른 하나는 다중회귀(Multiple Linear Regression)입니다.
선형회귀는 하나의 독립변수를 사용하여 Y라는 독립 변수를 설명하거나 예측하는 통계모델을 의미합니다. 반면에 다중회귀는 2개 이상의 독립변수를 사용하여 Y라는 결과를 설명하거나 예측하는 통계모델입니다.
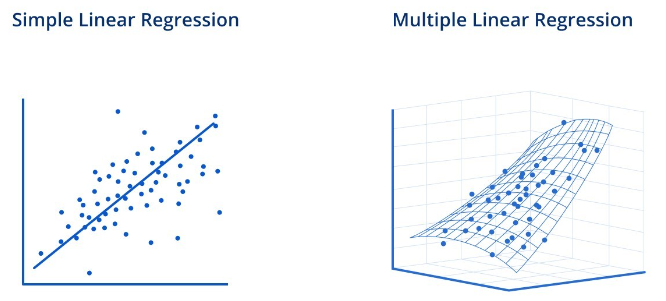
1.2.1 선형 회귀모델
선형회귀 모델은 종속변수 X와 독립변수 Y 2개의 변수간의 관계를 정의하는 모델입니다. 선형회귀는 하나의 변수의 변화가 다른 변수에 대해 어떤 영향을 끼치는지 그래프위에 경사가 있는 선으로 표현할 수 있습니다. 모든 변수들은 종속변수 Y에 대해서 하나의 상관관계를 가집니다. 예를 들어 y = 3x+7이라는 선현회귀식이 존재한다면, y가 정해진다면, x는 하나의 값을 가지게 됩니다.
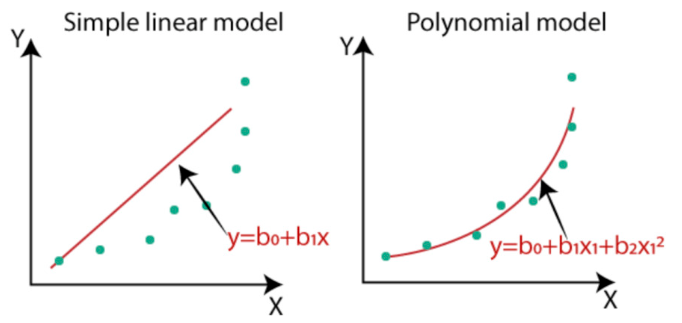
만일 두개의 변수의 상관관계까 선형을 따라가지 않는다면 비선형 회귀분석을 사용 할 수 있습니다. x를 일차식이 아닌 2차,3차식으로 만들어서 x의 값에 따라서 y의 값이 비선형적으로 예측 가능하도록 식을 만드는것입니다. 이를 다항식(Polynomial model)이라고 합니다. 다항 회귀모델은 단순 선형 회귀모델에 비해 더 복잡하지만 y의 값에 대해 유연하게 예측값을 정의할 수 있습니다.
1.2.2 회귀모델 생성 방법
그럼 회귀모델을 만드는 절차에 대해서 알아보도록 하겠습니다.
- 종속변수 x와 독립변수 y의 관계를 나타태는 임의의 수식을 설정합니다.

- 임의의 회귀식에서 구한 y hat값과 실제 y값의 차이(잔차)를 구합니다. 여기서 y hat의 값과 y의 잔차가 얼마나 큰지를에 관심이 있기 때문에 양수,음수에 영향을 받지 않도록 "잔차의 제곱의 합"을 구합니다.
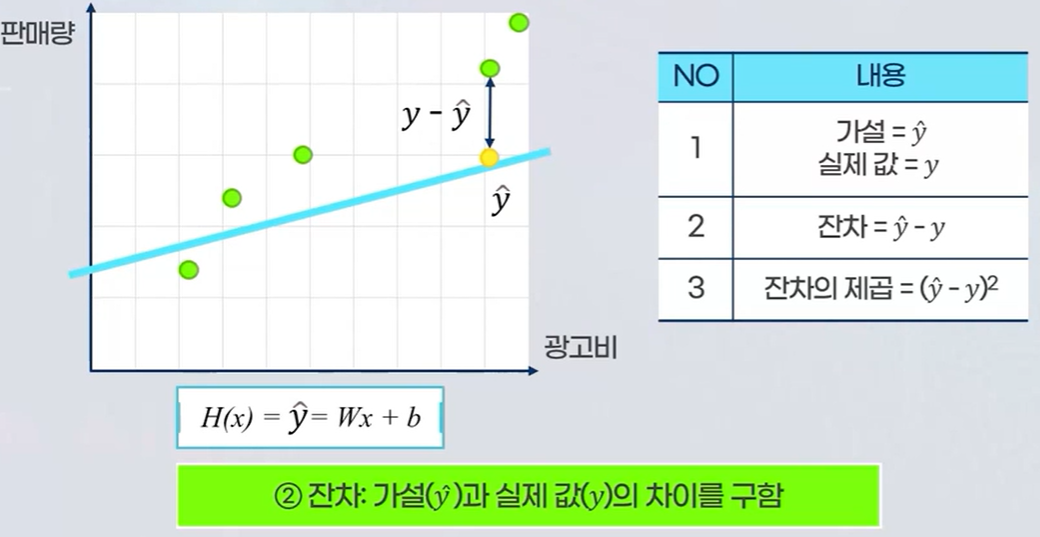
- 비용함수 : 가설의 y hat의 값과 실제 y값의 잔차의 제곱의 평균을 구합니다. 이를 "비용함수"라고 합니다.
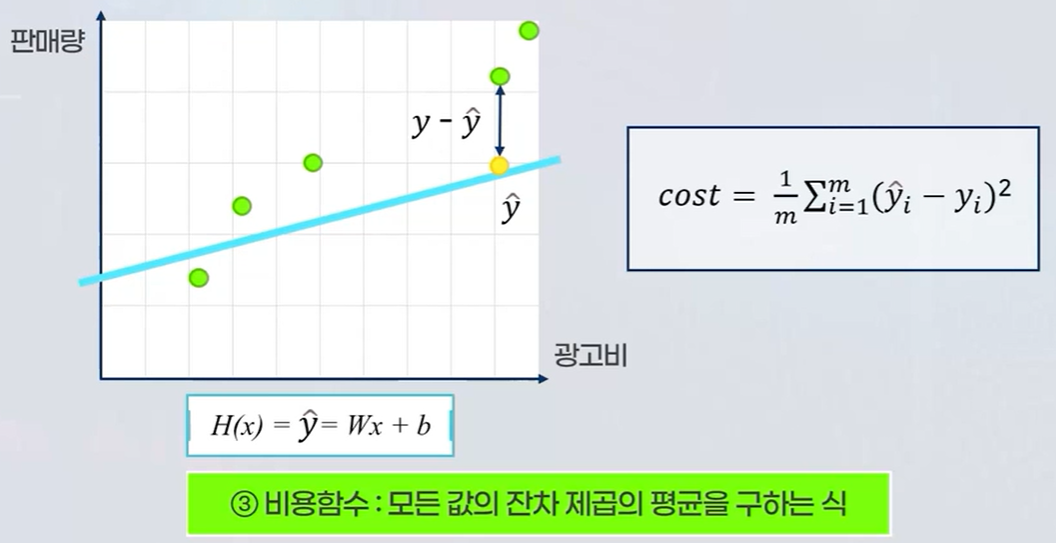
- 비용함수의 최소값을 구하기 위해 w에 대해 편미분하여 0이 되는 지점을 찾는 과정이 최적의 회귀식을 위한 w값을 구하느 과정이라고 할 수 있습니다. 잔차의 제곱의 합을 구하는 식에서 2차 방정식이 만들어지기 때문에 아래와 같은 포물선 그림이 만들어지고, 우리는 비용이 최소가 되는 값을 찾아야 하기 때문에 w값이 미분 했을 때 0이 되는 지점을 찾아야 합니다.

(여기서 편미분을 하는 이유는 w값(기울기)을 조정하면서 비용이 0이 되는 지점을 찾기 위해서 입니다.)
1.3 다중선형 회귀분석
만일 데이터간 복잡한 관계가 있다면, 관계를 설명하는데 있어서 하나 이상의 변수로 설명되어야 할것입니다. 이때 종속변수(y)를 하나 이상의 독립변수(x)를 사용하여 설명하려고 시도하는데 이를 "다중선형 회귀 모델"이라고 합니다. 쉽게 말해 복잡한 관계를 설명하기 위해 둘 이상의 종속변수와 하나의 종속변수 사이의 관계를 분석하는것이라고 할 수 있습니다.
여기서 주어진 독립변수를 모두 사용하는것보다, 종속변수에 영향을 주는 독립변수를 찾아 회귀식을 구성하는것이 중요합니다.

1.3.1 다중선형 회귀분석 생성 방법
다중 회귀 분석에서는 여러가지 독립변수에 대해서 전처리 하는 과정을 거칩니다.
- 독립변수 선택과 전처리
독립변수 중 종속변수와의 상관관계를 분석하여 상관관계가 적은 독립변수를 제거하는 경우도 있으며, 독립변수 2개가 상호 연관성이 있는 경우도 있기 때문에, 이럴 경우 종속변수에 더 영향을 많이 끼치는 한가지만 사용하는것이 효율적인 분석이 될 수 있습니다.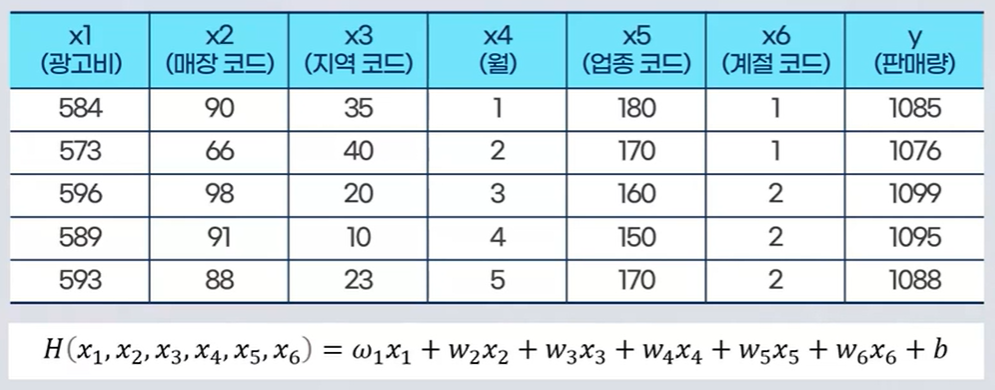
1.4 회귀모델의 평가
그럼 회귀 모델을 평가하는 방법에 대해서 알아 보겠습니다.
회귀모델의 평가 절차는 아래의 그림과 같으며 테스트 x 독립변수에 대해서 예측한 y hat의 결과와 실제 y값을 비교하는 방식으로 이뤄집니다. 여기서 분류모델처럼 y hat과 y값이 일치하는지가 중요한것이 아니라 예측치 y hat과 실제값 y의 차이가 적게 나타나는지를 확인하는 방향으로 이뤄져야 합니다.

회귀모델의 주요 평가 지표는 아래와 같습니다.

- MSE(Mean Squared Error)
- y hat과 y값의 차이의 제곱을 하기 때문에 모델의 예측값과 실제값의 차이의 면적을 구합니다.
- y hat과 y값의 차이의 제곱을 하기 때문에 이상치에 민감하기 때문에 오차의 민감도를 확인하기 위한 지표입니다.
- 모델의 예측이 얼마나 분산되어 있는지를 알려주며, 값이 작을수록 좋은 모델입니다.
- MAE(Mean Absolute Error)
- 모델의 예측값과 실제값의 차이의 절대값의 평균을 구합니다.
- 가장 직관적으로 알 수 있는 지표로, 해석이 용이합니다.
- 값이 작을수록 좋은 모델입니다.
- R-Square(Conefficient of determination)
- 현재 사용하고 있는 독립변수가 종속변수의 분산을 얼마나 줄여
- 모델이 종속변수의 변동을 얼마나 잘 설명하는지 나타내는 값입니다.
- 1에 가까울 수록 좋은 모델입니다.
1.5 회귀모델의 활용
회귀모델을 통해서 아래와 같은 정보를 알 수 있습니다.
- 미래의 값을 예측하거나 파악하고 싶을때
예시 : 집값과 관련된 여러 변수(집 크기, 위치, 방의 개수, 편의시설)를 고려하여 미래의 집값을 예츨하는데 사용됩니다. - 2개 이상의 변수의 상관관계를 확인하고 싶을때
예시 : 광고비용과 제품 판매량 사이의 상관관계를 분석하여 효율적인 광고 전략을 수립할 수 있습니다. - 하나의 변수의 변화로 다른 변수가 어떻게 변하는지 이해하고 싶을 때
예시 : 특정 질병(혈압)에 대해 연령,체중,생활습관,주 운동횟수의 변화가 다른 변수에 어떤 영향을 끼치는지 확인 할 수 있어 이 데이터를 기반으로하여 예방 및 치료 전략을 개발할 수 있습니다.
그럼 다중회귀분석이 어떻게 사용되는지 한번 알아볼까요?
< 다중선형 회귀모델의 예시 >
- 만일 옥수수의 생산량을 온도,강수량 그리고 다른 독립변수를 사용하여 예측하고 싶을때
- 만일 옥수수의 생산량을 조절하고 싶을때 각각의 종속변수들이 얼마나 강한 상관관계를 나타내는지 알고 싶을 때
다중 선형회귀는 각각의 독립변수 간의 강한 상관관계를 나타내지는 않습니다. 단지 각각의 종속변수들이 하나의 독립변수에 대해 어떤 상관관계가 있는지 혹은 각각의 종속변수들이 독립변수에 대해 어떠한 영향을 주는지 추측할 뿐입니다.
1.6 상관분석 vs 회귀분석
회귀분석을 공부하다보면 상관분석이라는 단어에 대해서 들어보게 될텐데요, 가끔 이 둘을 같은 개념이라고 혼동하는 경우가 있어서 둘의 개념에 대해서 간단히 정리해보고자 합니다.

* 상관관계는 "x와 y의 관련 정도를 확인하는 분석으로 x가 y와 어떤 상관관계가 있는지 분석하는 지표"라고 할 수 있습니다. 예를들어 공부하는 시간과 성적과의 상관관계가 있는지 알아보고 싶다면 공부시간과 성적 데이터를 산포도와 상관계수를 통해 관계성을 파악하여 양의 상관관계인지, 음의 상관관계인지 혹은 관계가 없는지 알아 볼 수 있습니다.
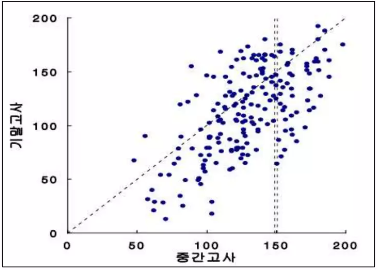

* 회귀분석은 "x가 y에 주는 영향을 추정하여 결과를 예측하는 분석 지표"라고 할 수 있습니다. 예를들어 공부하는 시간을 가지고 성적을 예측하고자 할 때, 공부시간과 성적의 회귀식을 구하여 공부한 시간을 가지고 어떤 성적을 받을 수 있는지 예측해 볼 수 있습니다.회귀분석을 통해 독립변인에 따른 종속변인의 변화를 예측할 수 있는 회귀식을 얻을 수 있게 됩니다.

이렇게 머신러닝의 회귀모델에 대해서 알아봤습니다.
혹시라도 정정할 내용이나 추가적으로 필요하신 정보가 있다면 댓글 남겨주시면 감사하겠습니다.
오늘도 Jindory 블로그에 방문해주셔서 감사합니다.
[참조]
- [멀티 캠퍼스] 핵심만 쏙! 실무에 바로 적용하는 머신러닝
'개발 > AI' 카테고리의 다른 글
| [AI] 연관분석 (0) | 2024.05.13 |
|---|---|
| [AI] 군집분석 (0) | 2024.05.08 |
| [AI] 모델 성능 개선 (0) | 2024.05.02 |
| [AI] 분류모델 (0) | 2024.04.06 |
| [AI] 머신러닝이란? (0) | 2024.04.06 |