![[AI] 머신러닝이란?](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdn%2FpsJZt%2FbtsGrckuscF%2FR6tIOXTJpei3tp3liKGPm0%2Fimg.png)
안녕하세요. 개발자 Jindory입니다.
오늘은 머신러닝에 대해서 글을 작성해보려고 합니다.
글에 앞서 본 글은 멀티캠퍼스의 "핵심만 쏙! 실무에 바로 적용하는 머신러닝"의 강의를 참고하여 작성한 내용임을 밝힙니다.
[ 글 작성 이유 ]
AI 관련 강의를 수강하며, 머신러닝과 관련된 개념 및 설명을 정리하고자 작성하게 되었습니다.
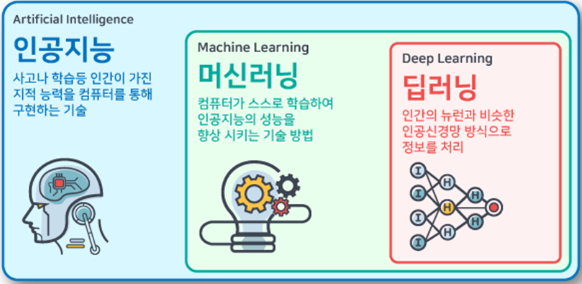
1. 머신러닝(Machine Learning)이란?
출처 : https://hyeonjiwon.github.io/machine%20learning/ML-1/
머신러닝은 데이터에서 규칙을 자동으로 학습하는 알고리즘을 연구하는 분야입니다. Machine과 Learning의 합성어로 데이터를 기반으로 컴퓨터가 스스로 학습하고 지능적인 결정을 내리는 기술을 의미합니다. 머신러닝의 특징을 아래와 같이 찾아봤습니다.
- 인공지능(AI)의 하위 개념입니다.
- 대규모 데이터셋에서 패턴과 상관관계를 찾고, 분석을 토대로 최적의 의사결정과 예측을 수행하도록 학습 및 훈련하여 만들어지는 알고리즘의 하나입니다.
- 기계가 스스로 학습하는 알고리즘을 만드는 학습입니다.
- 컴퓨터가 수 많은 데이터 입력값을 받아서 결과값을 도출하는 알고리즘을 만드는 과정입니다.
2. 머신러닝 프로세스
머신러닝을 수행하는 과정을 정리하면 크게 문제정의, 데이터 전처리, 모델 학습, 모델 평가 이렇게 4가지로 정리할 수 있습니다. 각각의 내용에 대해서 하나씩 정리하며 알아보도록 하겠습니다.
2.1 문제정의
모든 문제를 머신러닝으로 해결할 수 있는것은 아니기 때문에 머신러닝으로 해결할 수 있는 문제 유형인지 아닌지 파악하여 해당 문제를 머신러닝으로 해결할 수 있는 문제인지 먼저 정의를 먼저 해야합니다. 아래의 질문들은 머신러닝으로 해결할 수 있는지 판단하는데 도움이 되는 질문들입니다.
- 데이터를 사용하여 어떤 결과를 도출하고 싶은가?
- 카테고리가 있는 결과값인가? 숫자로 나오는 결과값인가? 범위형 결과값인가?
- 머신러닝으로 해결할 수 있는 문제인가?
- 데이터가 존재하는가?
- 입력과 출력이 존재하는가?
- 문제가 복잡하지 않고 간단하게 해결할 수 있는 문제는 아닐까?
- 데이터는 수집할 수 있는가?
- 머신러닝을 학습할 수 있는 데이터를 확보할 수 있는가?
- 데이터 사용에 있어서 제한은 없는가?
- 머신러닝을 도입할 필요가 있는가?
- 머신러닝을 도입하지 않고도 잘 해결되는 문제에 꼭 머신러닝을 도입해야하는가?
- 문제 유형

- 지도학습(Supervised Learning)
- 분류(Classification)
- 정의 : 분류는 이산적인 결과를 예측하는데 사용되는 머신러닝입니다.
- 설명 : 주어진 데이터를 여러 클래스 또는 범주로 분류합니다.
- 예시 : 스팸 메일 여부를 판단하거나 이미지에서 손톱인지 아닌지 분류하는 작업이 있습니다.

- 회귀(Regression)
- 정의 : 숫자 값을 예측하는데 사용되는 머신러닝 방법입니다.
- 설명 : 주어진 입력 데이터와 해당 입력에 대한 결과(종속 변수) 사이의 관계를 학습하여, 새로운 입력에 대한 결과 값을 예측합니다.
- 예시 : 온도와 귀뚜라미가 우는 횟수로 귀뚜라미가 우는 최적의 온도를 찾을 수 있습니다.

- 분류(Classification)
- 비지도학습(Un-Supervised Learning)
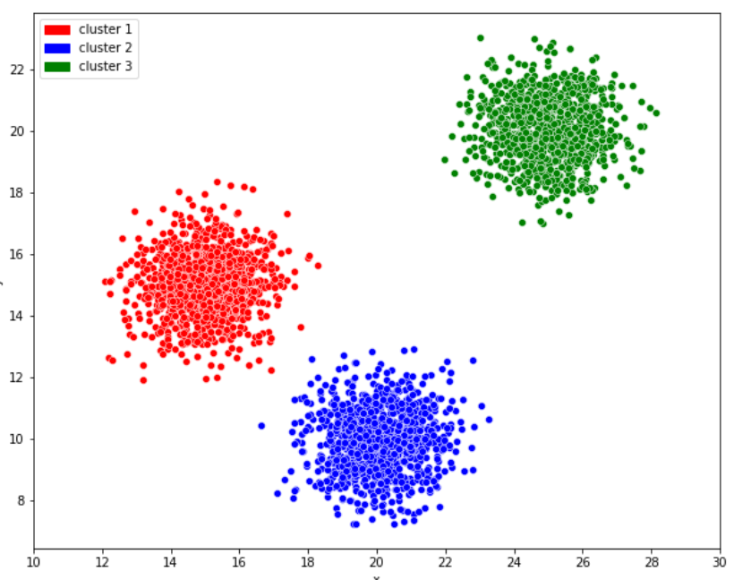
- 군집(Clustering)
- 정의 : 유사한 데이터를 그룹으로 묶는데 사용되는 머신러닝입니다.
- 설명 : 비슷한 특성을 가진 데이터를 그룹으로 묶어서 패턴을 찾거나 데이터를 정리합니다.
- 예시 : 고객들을 구매 패턴에 따라 군집화하여 마케팅 전략을 수립할 수 있습니다.
- 연관규칙(Association Rules)
- 정의 : 연관 규칙은 데이터 간의 관계를 찾는데 사용되는 머신러닝입니다.
- 예시 : 상품 구매 데이터에서 특정 상품들이 함께 자주 구매되는 경향을 찾아내는 작업이 있을 수 있습니다.

- 군집(Clustering)
2.2 데이터 전처리
머신러닝을 학습시키기 위해서는 데이터가 필요합니다. 머신러닝에 학습할 데이터를 수집하여 바로 학습시키는 것이 아니라 수집한 데이터를 분석하고 처리하기에 적합한 형태로 만드는 과정을 거치게 됩니다. 이러한 일련의 과정을 데이터 전처리라고 하며 데이터분석 혹은 데이터 마이닝이라고 합니다.
- 정의 : 데이터 분석을 위해 수집한 데이터를 분석에 적합한 형태로 가공하는 과정
- 효과 : 데이터 분석 결과의 정확도를 높이고, 분석 시간을 단축하는 중요한 역할을 함.
- 종류
- 데이터 정제
- 결측치 처리
- 결측치(Missing Value)란 없거나 비어있는 값을 의미합니다.
- 결측치가 있는 경우 해당 부분을 제거하거나 대체하는 방법을 사용합니다.
- 중복데이터
- 똑같은 데이터가 중복되어 있다면 편향된 결과를 낼 수 있기 때문에 사전처리 필요.
- 이상치
- 이상치(Outlier)란 일반적인 패턴에서 벗어난 값으로, 다른 관측치값들과 동떨어진 값을 가집니다.
- 이상치 값을 적절히 처리하지 않으면 일반적인 데이터에 대해서 잘못된 결과값을 도출하는 알고리즘이 만들어 질 수 있으므로 적절한 전처리가 필요합니다.
- 결측치 처리
- 데이터 병합
- 2개 이상 데이터 객체를 하나의 데이터 객체로 합치는 작업

- 2개 이상 데이터 객체를 하나의 데이터 객체로 합치는 작업
- 데이터 분할
- 모델을 만들기 위해 학습시킬 학습데이터와 테스트 할 때 사용할 테스트용 데이터를 구분합니다.
- 지도 학습의 경우에는 Feature와 Label을 나누는 작업이 필요합니다.
- 데이터 정제

2.3 학습
컴퓨터가 데이터를 기반으로 학습하고 성능을 향상시킬 수 있도록 하는 알고리즘과 기술을 개발하는 과정을 말합니다.
- 학습의 예시
- 분류모델

- 회귀모델

- 군집모델

- 연관모델
- 분류모델
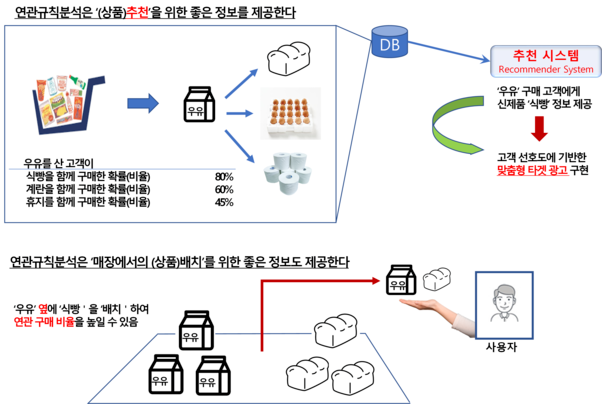
2.4 모델평가
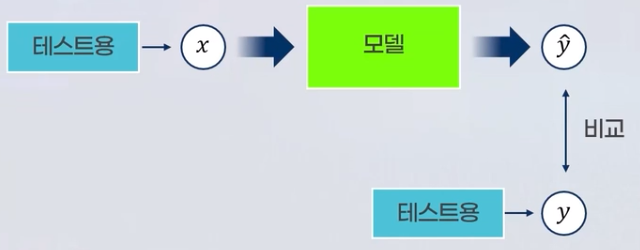
모델평가란 모델을 개발하고 테스트 하는 과정에서 반복적으로 수행하며, 다양한 측면에서 모델의 성능을 평가하고 실제 문제를 해결에 적용 가능한 모델을 개발하는 과정입니다.성능평가 방법에는 아래와 같은 방법이 있습니다.
- 오차 행렬(Confusion Matrix) : 실제 클래스와 모델의 예측 결과를 행렬로 나타내어 성능을 평가합니다.

- 정확도(Accuracy) : 모델이 예측한 결과와 실제 정답이 얼마나 일치하는지 측정합니다. 정확도는 일반적으로 분류 문제에 사용됩니다.
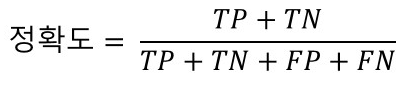
- 정밀도(Precision)과 재현율(Recall) : 이진 분류에서 중요한 지표입니다.
- 정밀도 : 모델이 양성으로 예측한것 중에서 실제로 양성인 비율

- 재현율 : 실제 양성 중에서 모델이 양성으로 예측한 비율

- 정밀도 : 모델이 양성으로 예측한것 중에서 실제로 양성인 비율
- F1 스코어(F1 Score) : 정밀도와 재현율의 조화 평균입니다. 불균형한 클래스 분포에서 유용합니다.
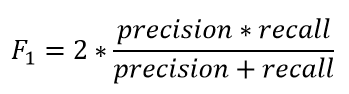
- ROC(Receiver Operating Characteristic Curve)와 AUC(Area Under the Curve) : 이진 분류에서 모델의 성능을 시각화 하고 평가하는 방법입니다.
- ROC
- ROC 커브는 머신 러닝 모델의 성능을 평가하는 그래프 입니다.
- ROC 커브의 가로축에 거짓 양성률(FPR)을, 세로축에 참 양성율(TPR)을 나타냅니다.
- TPR은 양성을 정확시 예측한 비율이고, FPR은 음성을 양서으로 잘못 예측한 비율입니다.
- ROC 커브는 모델의 성능을 시각적으로 확인할 때 사용됩니다.
- AUC
- ROC 커브 아래의 면적을 구한 값입니다.
- AUC는 0부터 1사이의 값을 가지며, 높을수록 더 좋은 분류 성능을 의미합니다.
- AUC는 모델의 성능을 비교하거나 최적의 임계값을 찾는데 사용됩니다.

- ROC
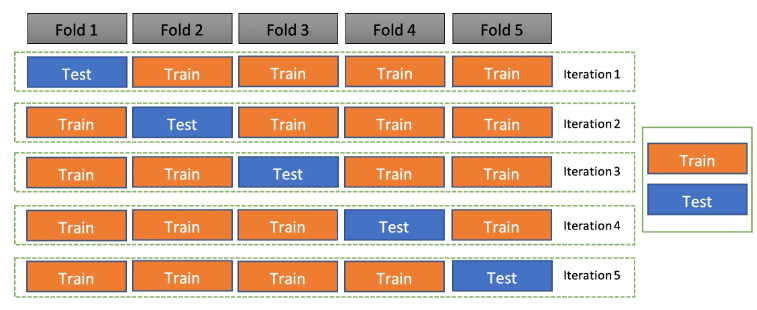
- 교차 검증(Cross-Validation) : 모델의 일반화 성능을 평가하기 위해 데이터를 여러 부분을 나누어 학습 과 검증을 번복하는 방법입니다.
3. 정리
위와 같이 머신러닝을 도입하는 과정에 대해서 아래와 같이 하나의 그림으로 정리할 수 있습니다.

- 문제정의 : 머신러닝을 도입하기 전 문제에 대해 정의하고 머신러닝을 도입할지에 대해서 검토하는 단계입니다. 아래의 질문에 대해 확인하여 머신러닝을 도입할지 여부에 대해서 판단을 내리는 단계입니다.
- 머신러닝으로 해결할 수 있는 문제인가?
- 머신러닝에 사용할 데이터가 있는가?
- 정말로 머신러닝을 도입해야하는 문제인가?
- 데이터 전처리 : 수집한 데이터를 머신러닝에 학습시키기 전에 가공하는 단계입니다.
- 평균에서 벗어난 특이한 값(이상치)와 값이 없는 데이터(결측치)에 대해서 제거하거나 다른 값으로 대체
- 분할된 데이터 중 병합하여 데이터값을 하나의 Feature로 만들거나, 하나의 데이터를 두개 이상으로 분할하여 여러개의 Feature로 생성
- 데이터를 학습용과 테스트용으로 나누고, Feature(x)와 Label(y)로 분할
- 학습 : 전처리를 마친 데이터를기반으로 학습하고 성능을 향상시킬 수 있도록 하는 알고리즘과 기술을 개발하는 단계입니다.
- 학습용 데이터만 사용하여 머신러닝 모델을 학습시켜 원하는 값을 도출하도록 성능을 개선
- 평가 : 만들어진 모델이 실제로 예측값을 잘 도출하는지 확인 및 검증하는 단계
- 머신러닝 모델이 도출한 결과와 실제값을 비교하며, 모델이 잘 동작하는지 확인
이렇게 머신러닝의 개념 및 프로세스에 대해서 알아봤습니다.
혹시라도 정정할 내용이나 추가적으로 필요하신 정보가 있다면 댓글 남겨주시면 감사하겠습니다.
오늘도 Jindory 블로그에 방문해주셔서 감사합니다.
[참조]
- [멀티 캠퍼스] 핵심만 쏙! 실무에 바로 적용하는 머신러닝
- https://velog.io/@shshin/%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D-%EC%99%84%EB%B2%BD%EA%B0%80%EC%9D%B4%EB%93%9C-3%EA%B0%95
머신러닝 완벽가이드 3강
평가 > 머신러닝은 데이터 가공/변환, 모델 학습/예측 그리고 평가의 프로세스로 구성된다. 앞 장의 타이타닉 생존자 예제에서는 모델 예측 성능의 평가를 위해 정확도(Accuracy)를 이용했다. 머신
velog.io
'개발 > AI' 카테고리의 다른 글
| [AI] 연관분석 (0) | 2024.05.13 |
|---|---|
| [AI] 군집분석 (0) | 2024.05.08 |
| [AI] 모델 성능 개선 (0) | 2024.05.02 |
| [AI] 회귀모델 (0) | 2024.04.10 |
| [AI] 분류모델 (0) | 2024.04.06 |